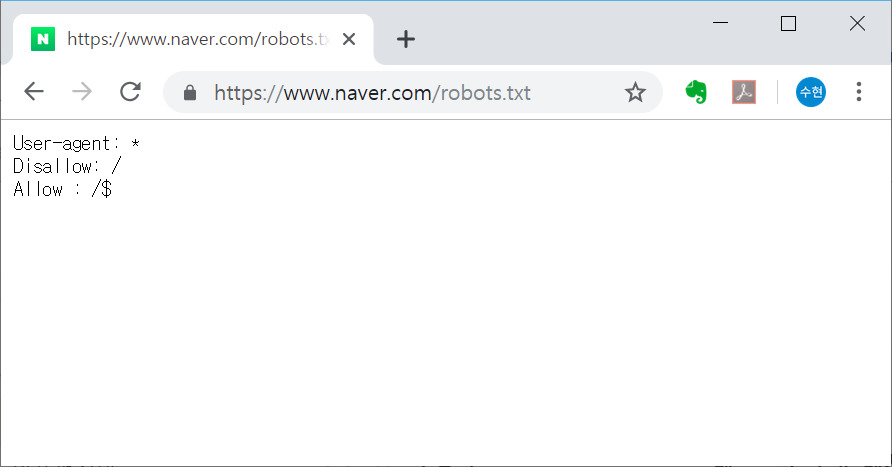
위키피디아 한국어 페이지에서 "평화의 소녀상"을 검색하면 다음과 같은 화면이 나타난다. 해당 URL을 requests 모듈을 이용하여 접속하고, html 소스를 가져온다.

BeautifulSoup 클래스의 find( ) 메소드에 HTML 요소의 태그 이름(‘img’)을 전달하면, 해당 태그 부분을 찾아서 객체로 return 해준다. find( ) 명령은 HTML 문서에서 가장 처음으로 만나는 태그를 한 개 찾는다. 앞의 위키피디아 화면에서 가장 먼저 나오는 사진(img 태그)은 "주한 일본 대사관 앞 평화비"라는 설명이 붙어 있는 사진이다.
"평화의 소녀상, 속초"라는 설명이 있는 사진을 나타내는 ‘img’ 태그를 선택하려면, attrs 매개변수에 해당 태그에만 해당하는 고유의 속성을 추가해야 한다. 개발자 도구를 이용하여 해당 태그를 확인할 수 있는데, alt 속성 값으로 이미지 소스 URL 값을 갖는다. 이 속성을 find( ) 메소드의 attrs 매개변수에 입력하는 방식으로, 특정 태그를 선택할 수 있다.
import requests
from bs4 import BeautifulSoup
url = "https://ko.wikipedia.org/wiki/%ED%8F%89%ED%99%94%EC%9D%98_%EC%86%8C%EB%85%80%EC%83%81"
resp = requests.get(url)
html_src = resp.text
soup = BeautifulSoup(html_src, 'html.parser')
photo_first = soup.find(name='img')
print(photo_first)
print("\n")
photo_sockcho = soup.find(name='img', attrs={'src':'//upload.wikimedia.org/wikipedia/commons/thumb/1/16/%ED%8F%89%ED%99%94%EC%9D%98%EC%86%8C%EB%85%80%EC%83%81%28Statute_of_Peace%29.jpg/220px-%ED%8F%89%ED%99%94%EC%9D%98%EC%86%8C%EB%85%80%EC%83%81%28Statute_of_Peace%29.jpg'})
print(photo_sockcho)
실행 결과는 다음과 같다. 두 개의 img 태그를 찾아서 내용을 확인할 수 있다. 이처럼, find( ) 메소드는 특정한 태그를 하나만 찾는 경우에 사용되고, 메모리 관리 측면이나 실행 시간에서 유리하다는 장점을 갖는다.
| <img alt="" class="thumbimage" data-file-height="3000" data-file-width="4000" decoding="async" height="173" src="//upload.wikimedia.org/wikipedia/commons/thumb/3/36/Japanese_Embassy_in_Seoul_and_watched_from_behind_a_bronze_statue_of_comfort_women.JPG/230px-Japanese_Embassy_in_Seoul_and_watched_from_behind_a_bronze_statue_of_comfort_women.JPG" srcset="//upload.wikimedia.org/wikipedia/commons/thumb/3/36/Japanese_Embassy_in_Seoul_and_watched_from_behind_a_bronze_statue_of_comfort_women.JPG/345px-Japanese_Embassy_in_Seoul_and_watched_from_behind_a_bronze_statue_of_comfort_women.JPG 1.5x, //upload.wikimedia.org/wikipedia/commons/thumb/3/36/Japanese_Embassy_in_Seoul_and_watched_from_behind_a_bronze_statue_of_comfort_women.JPG/460px-Japanese_Embassy_in_Seoul_and_watched_from_behind_a_bronze_statue_of_comfort_women.JPG 2x" width="230"/>
<img alt="" class="thumbimage" data-file-height="2268" data-file-width="4032" decoding="async" height="124" src="//upload.wikimedia.org/wikipedia/commons/thumb/1/16/%ED%8F%89%ED%99%94%EC%9D%98%EC%86%8C%EB%85%80%EC%83%81%28Statute_of_Peace%29.jpg/220px-%ED%8F%89%ED%99%94%EC%9D%98%EC%86%8C%EB%85%80%EC%83%81%28Statute_of_Peace%29.jpg" srcset="//upload.wikimedia.org/wikipedia/commons/thumb/1/16/%ED%8F%89%ED%99%94%EC%9D%98%EC%86%8C%EB%85%80%EC%83%81%28Statute_of_Peace%29.jpg/330px-%ED%8F%89%ED%99%94%EC%9D%98%EC%86%8C%EB%85%80%EC%83%81%28Statute_of_Peace%29.jpg 1.5x, //upload.wikimedia.org/wikipedia/commons/thumb/1/16/%ED%8F%89%ED%99%94%EC%9D%98%EC%86%8C%EB%85%80%EC%83%81%28Statute_of_Peace%29.jpg/440px-%ED%8F%89%ED%99%94%EC%9D%98%EC%86%8C%EB%85%80%EC%83%81%28Statute_of_Peace%29.jpg 2x" width="220"/> |
'파이썬 데이터 분석 > 웹 스크래핑' 카테고리의 다른 글
| [6] 파이썬 웹 스크래핑 - BeautifulSoup 클래스 객체 (0) | 2019.08.05 |
|---|---|
| [6] 파이썬 웹 스크래핑 - 로봇 배제 표준(robots.txt) (0) | 2019.08.02 |
| [5] 파이썬 웹 스크래핑 - requests 모듈, HTML 소스코드 확인 (0) | 2019.08.01 |
| [4] 상장사 재무제표 수집 (pandas) (0) | 2018.08.16 |
| [3] 네이버 주식 시세 (주가 정보) 스크래핑(scraping) 예제 (0) | 2018.07.02 |