웹사이트에서 정보를 가져올 때, 기본적인 윤리규정과 저작권 등 법률적 이슈에 대하여 유의하여야 한다.
위키피디아(https://ko.wikipedia.org/wiki/)는 로봇 배제 표준에 대하여 “웹 사이트에 로봇이 접근하는 것을 방지하기 위한 규약으로, 일반적으로 접근 제한에 대한 설명을 robots.txt에 기술한다.” 라고 말한다. 무분별한 서버 접속은 서버의 안정성을 해치기도 하고, 대부분의 웹 사이트들은 로봇배제표준을 제정하여 게시하고 있다.

권고안이기는 하지만 웹 페이지에 접근하기 전에 반드시 로봇 배제 표준을 확인하고 가이드라인을 준수할 필요가 있다.또한, 사이트에 반복적으로 접속하는 행위는 사이트를 공격하는 행위로 받아들여질 수 있기 때문에 서버에 부담을 주지 않는 선에서 제한하는 것이 필요하다.
마지막으로, 취득한 데이터를 임의로 배포하거나 변경하는 등의 행위는 저작권을 침해할 가능성이 있기 때문에, 로봇배제표준 이외에 저작권 규정을 준수해야 한다.
로봇배제표준을 확인하는 가장 간단한 방법은 웹브라우저 주소창에 "홈페이지 메인 주소/robots.txt"라고 입력하는 것이다.
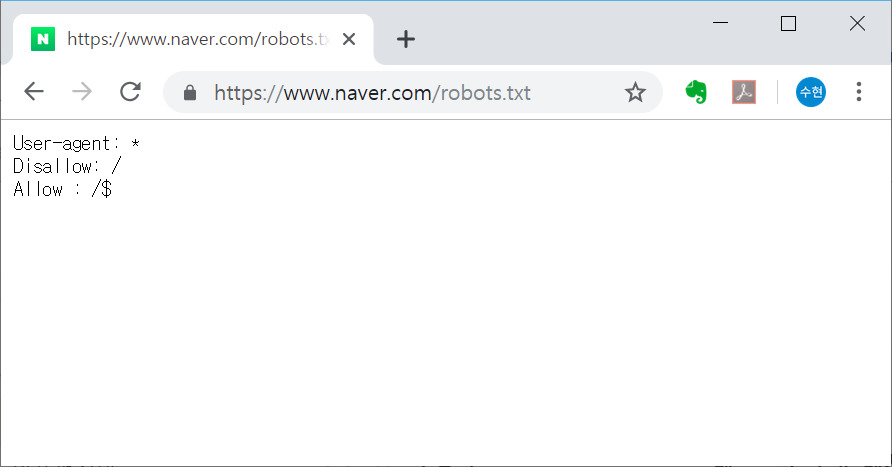
네이버(www.naver.com)의 경우는 다음과 같다. 네이버는 기본적으로 스크래핑(크롤링) 봇의 접근을 금지하고 있다.
다만, 루트 디렉터리(www.naver.com/)에 대해서는 허용하고 있는 것으로 볼 수 있다. $ 표시는 웹 주소의 마지막을 뜻하기 때문에, 루트 디렉터리의 경우 Allow하고 있다고 해석할 수 있다.
로봇배제표준에 대한 상세 설명은 다음 위키피디아 링크를 참조하기 바란다.
https://ko.wikipedia.org/wiki/%EB%A1%9C%EB%B4%87_%EB%B0%B0%EC%A0%9C_%ED%91%9C%EC%A4%80
'파이썬 데이터 분석 > 웹 스크래핑' 카테고리의 다른 글
| [7] 파이썬 웹 스크래핑 - find 메소드로 <img> 태그 선택하기 (1) | 2019.08.08 |
|---|---|
| [6] 파이썬 웹 스크래핑 - BeautifulSoup 클래스 객체 (0) | 2019.08.05 |
| [5] 파이썬 웹 스크래핑 - requests 모듈, HTML 소스코드 확인 (0) | 2019.08.01 |
| [4] 상장사 재무제표 수집 (pandas) (0) | 2018.08.16 |
| [3] 네이버 주식 시세 (주가 정보) 스크래핑(scraping) 예제 (0) | 2018.07.02 |